Отказоустойчивость и аварийное восстановление Global ERP#
Важно
Документ не заменяет детальные пошаговые инструкции уровня runbook для конкретных инцидентов. Такие инструкции должны вестись отдельно и поддерживаться в актуальном состоянии администраторами подсистем. Настоящее руководство описывает общий подход к обеспечению высокой доступности (HA) и аварийному восстановлению (DR) системы Global ERP, задаёт рамочную модель, архитектурные требования и единый порядок принятия решений.
Global ERP поддерживает непрерывную эксплуатацию в режиме 24x7 с допустимыми регламентными перерывами на техническое обслуживание. Непрерывность работы обеспечивается механизмами высокой доступности и аварийного восстановления: резервированием ключевых компонентов, репликацией данных, мониторингом, резервным копированием и регламентированными процедурами переключения при отказах.
Термины и принципы#
Высокая доступность (HA, High Availability) - это способность системы продолжать работу при отказе отдельных компонентов без полной остановки сервиса. Обычно речь идёт об отказе ноды, диска, процесса, сетевого сегмента или экземпляра приложения. Цель HA - минимизировать простой сервиса и не допустить эскалации локального сбоя в полноценную аварию.
Аварийное восстановление (DR, Disaster Recovery) - это способность восстановить работоспособность системы после серьёзной аварии, включая полный отказ кластера, потерю хранилища, разрушение базы данных или недоступность целого ЦОДа. Цель DR - восстановить сервис в предсказуемые сроки и с контролируемой потерей данных.
Для оценки готовности системы используются два ключевых показателя.
RTO (Recovery Time Objective) - максимально допустимое время восстановления после аварии.
RPO (Recovery Point Objective) - максимально допустимый объём потери данных, выраженный во времени между последним согласованным состоянием и моментом отказа.
При проектировании Global ERP необходимо исходить из следующих базовых принципов:
Отказоустойчивость не должна строиться только на резервных копиях; резервные копии являются последней линией восстановления, а не заменой репликации и резервирования;
Площадки должны быть действительно независимыми: две подсети в одном ЦОД с общей инженерной инфраструктурой нельзя считать двумя зонами доступности;
Используйте зоны доступности (Availability Zones) для обеспечения непрерывной работы. Зона доступности — это центр обработки данных с отдельным источником питания, системой резервного копирования и подключением к Интернету. Две подсети в одном ЦОД с общим источником питания нельзя считать двумя зонами доступности. Примером двух AZ могут служить два отдельных центра обработки данных в относительной близости друг к другу, которые имеют сетевое соединение с низкой сетевой задержкой и высокой пропускной способностью.
ЦОДов должны быть не менее двух, один из которых будет в другом регионе. Каждый дополнительный ЦОД - это усложнение и удорожание конструкции, однако при необходимости такая возможность существует.
Ключевые инфраструктурные компоненты - PostgreSQL, Kubernetes, NFS, балансировка, репозиторий артефактов и CI/CD - должны оцениваться как части единой цепочки восстановления;
Каждое проектное решение по HA/DR должно сопровождаться тестируемым сценарием переключения или восстановления;
Любая схема резервирования должна учитывать не только запуск инфраструктуры, но и возможность вернуть бизнес-функции, включая интеграции, фоновые задания, доступность файлов и согласованность данных.
Система должна поддерживать одновременный ввод и выборку данных с нескольких рабочих мест как в штатном режиме, так и после восстановления. Архитектура HA/DR должна гарантировать сохранение этой возможности при всех сценариях отказов.
Архитектура Global ERP построена как единый инстанс с общей моделью данных, единым контуром безопасности, централизованным НСИ и поддержкой сквозных бизнес-процессов. Все сценарии HA/DR должны сохранять эту целостность: при переключении на резервную площадку или восстановлении после аварии все прикладные контуры (бухгалтерия, кадры, производство, снабжение и др.) остаются согласованными, а данные — непротиворечивыми.
Производительность и масштабируемость являются неотъемлемой частью отказоустойчивости: штатная конфигурация Global ERP обеспечивает стабильную работу при тысяче активных сессий с временем отклика 1–3 секунды для типовых операций. Система прошла валидацию на нагрузке до 30 000 одновременных пользователей — этот запас масштабируемости должен учитываться при проектировании резервных площадок: после переключения или восстановления система обязана сохранять способность обрабатывать пиковую нагрузку без деградации пользовательского опыта.
Разделение функциональных модулей на отдельные инстансы рассматривается как специальный архитектурный сценарий, а не как обязательное условие эксплуатации. По умолчанию все прикладные контуры работают в рамках единого инстанса с общей моделью данных. При использовании распределённой архитектуры каждый инстанс должен иметь собственный контур HA/DR, а механизмы интеграции между ними — предусматривать буферизацию, повторную отправку и контроль целостности данных при сбоях связи или отказе одного из контуров.
Классификация аварийных ситуаций#
Рекомендуется ввести единую шкалу аварийных состояний:
Зелёная тревога - простой отказ, не приводящий к недоступности сервиса или вызывающий перебой не более 10 минут. Возможна частичная потеря функциональности. Обрабатывается автоматически.
Жёлтая тревога - отказ средней значимости. Перерыв в предоставлении сервиса до 4 часов. Требует ручного вмешательства администраторов.
Красная тревога - катастрофический отказ. Перерыв свыше 4 часов. Требует информирования и согласования с дирекцией по ИТ. При таких инцидентах остаётся риск превышения проектных значений RTO.
Роли и зоны ответственности#
Рекомендуемая модель ответственности:
Администратор Global ERP отвечает за эксплуатационную целостность платформы, контроль репликации прикладных экземпляров, координацию работ по DRP и общее ведение сценариев восстановления.
Системный администратор отвечает за работоспособность инфраструктурной основы: виртуализации, серверов, Kubernetes, NFS, резервного копирования, репликации и состояния репозиториев артефактов.
Администратор СУБД отвечает за PostgreSQL, репликацию, резервные копии базы, процедуры промоутинга реплик и восстановления данных.
Инженер DevOps отвечает за CI/CD, воспроизводимость развёртывания, доступность образов и поддержку эксплуатационных сценариев, связанных с Kubernetes и автоматизацией.
Сетевой администратор отвечает за маршрутизацию, DNS, сетевую связность между площадками и переключение пользовательского трафика.
Функциональные эксперты проверяют работоспособность бизнес-функций и интеграций после восстановления.
Архитектура#
Архитектура HA/DR для Global ERP должна опираться не на один механизм, а на комбинацию решений: резервирование узлов, репликацию данных, регулярные резервные копии, территориальное разнесение, автоматический мониторинг, а также повторяемые процедуры развертывания из репозитория артефактов. Именно сочетание этих механизмов и формирует реальную устойчивость системы.
Базовый вариант#
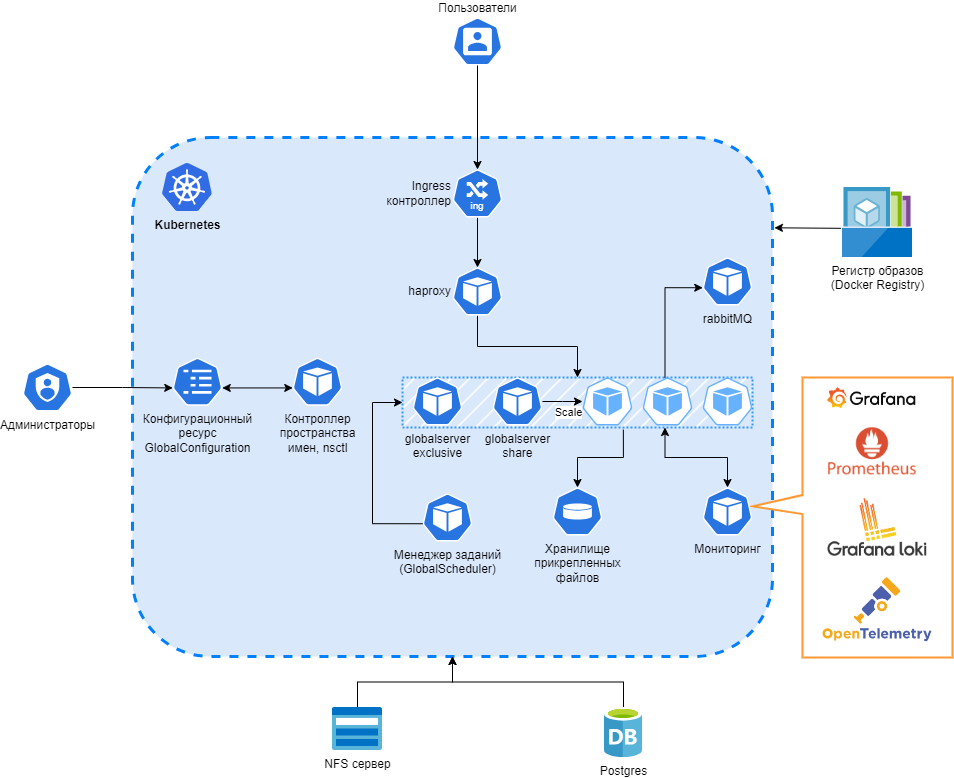
Kubernetes: 1 control-plane + N worker.
PostgreSQL: одиночный инстанс (без реплик).
Бекапы: экспорт манифестов K8s (namespaces + cluster-scoped), логические дампы PostgreSQL (актуально при размере БД <= 1.5 ТБ).
Базовый вариант подходит для систем, где требуется технологическая отказоустойчивость внутри одной площадки, но ещё не требуется полноценный межплощадочный DR-контур. В этом случае Kubernetes разворачивается как один control-plane и несколько worker-узлов, PostgreSQL работает как одиночный инстанс или в упрощённой схеме без удалённой реплики, а защита данных строится преимущественно на резервных копиях: логических или бинарных дампах БД, экспортируемых манифестах Kubernetes и копиях конфигурации приложения.
Такой вариант в большей степени допустим для пилотных сред, TEST/DEV-контуров. Для полноценного PROD его недостаточно, поскольку отказ СУБД, NFS или площадки приведёт к длительному восстановлению из бэкапов.
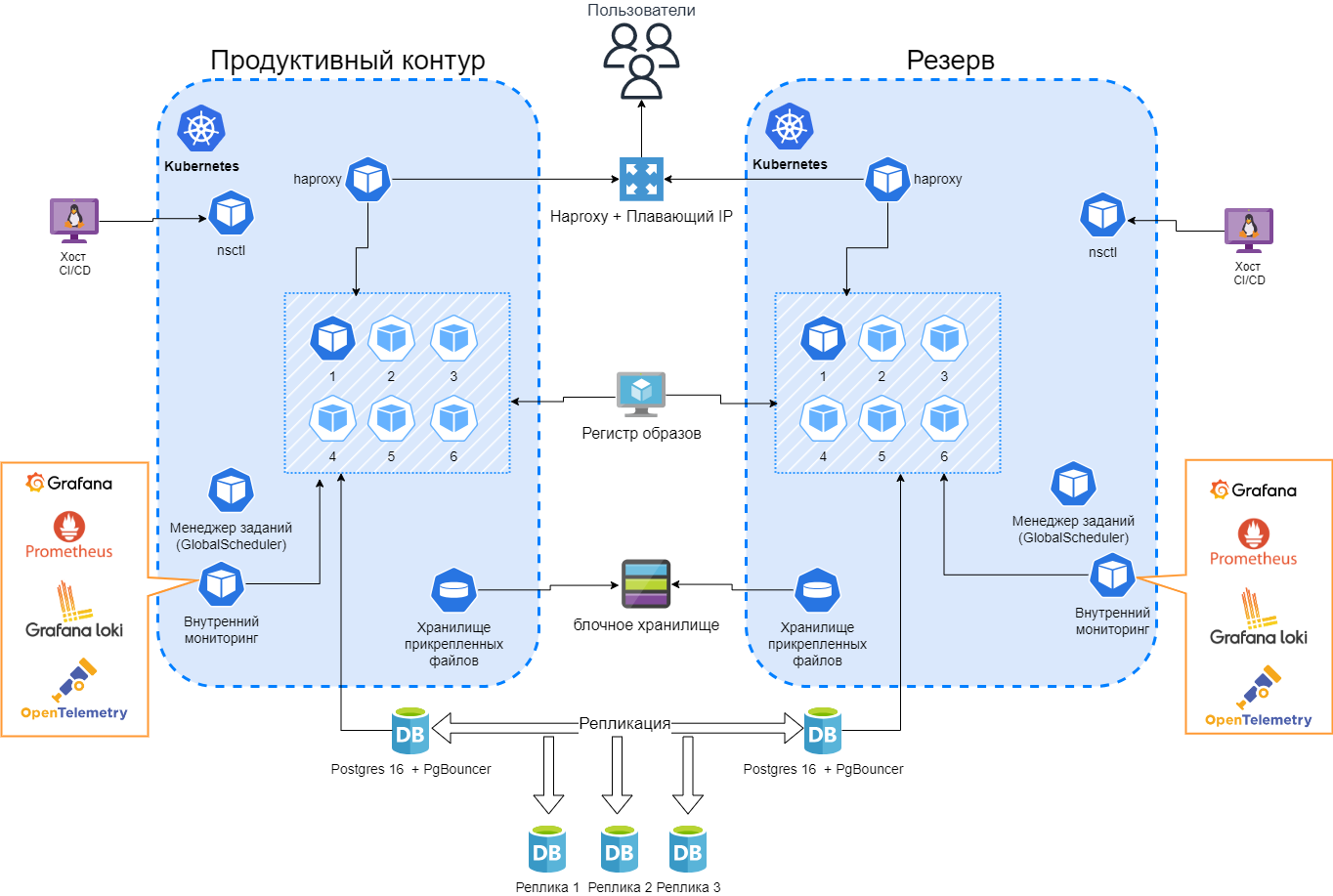
Вариант DR Active–Passive#
Модель: один ЦОД активен, второй «на паузе» с заранее выделенными ~50% ресурсов. При наступлении катастрофы необходимо время на развертывание ЦОДа на полную мощность.
Реестр образов: обязательные бекапы/репликации.
СУБД: асинхронная реплика на резерв(ы). Допускается задержка (минуты/часы). Реплик может быть несколько.
Переключение: автоматическое через HAProxy, полуавтоматическое (кнопка/скрипт), или ручное через DNS (пониженный TTL).
В модели Active–Passive основная площадка обслуживает нагрузку, а вторая площадка остаётся резервной. На резервной стороне поддерживаются реплики критичных данных и, при необходимости, заготовленная инфраструктура с неполной загрузкой ресурсов. При катастрофе основного ЦОДа резервная площадка активируется, после чего нагрузка перенаправляется на неё.
Этот вариант относительно прост в эксплуатации и обычно даёт лучший баланс между стоимостью и устойчивостью. Он хорошо подходит для систем, где допустимо ручное или полуавтоматическое переключение, а небольшой RPO, связанный с асинхронной репликацией, считается приемлемым.
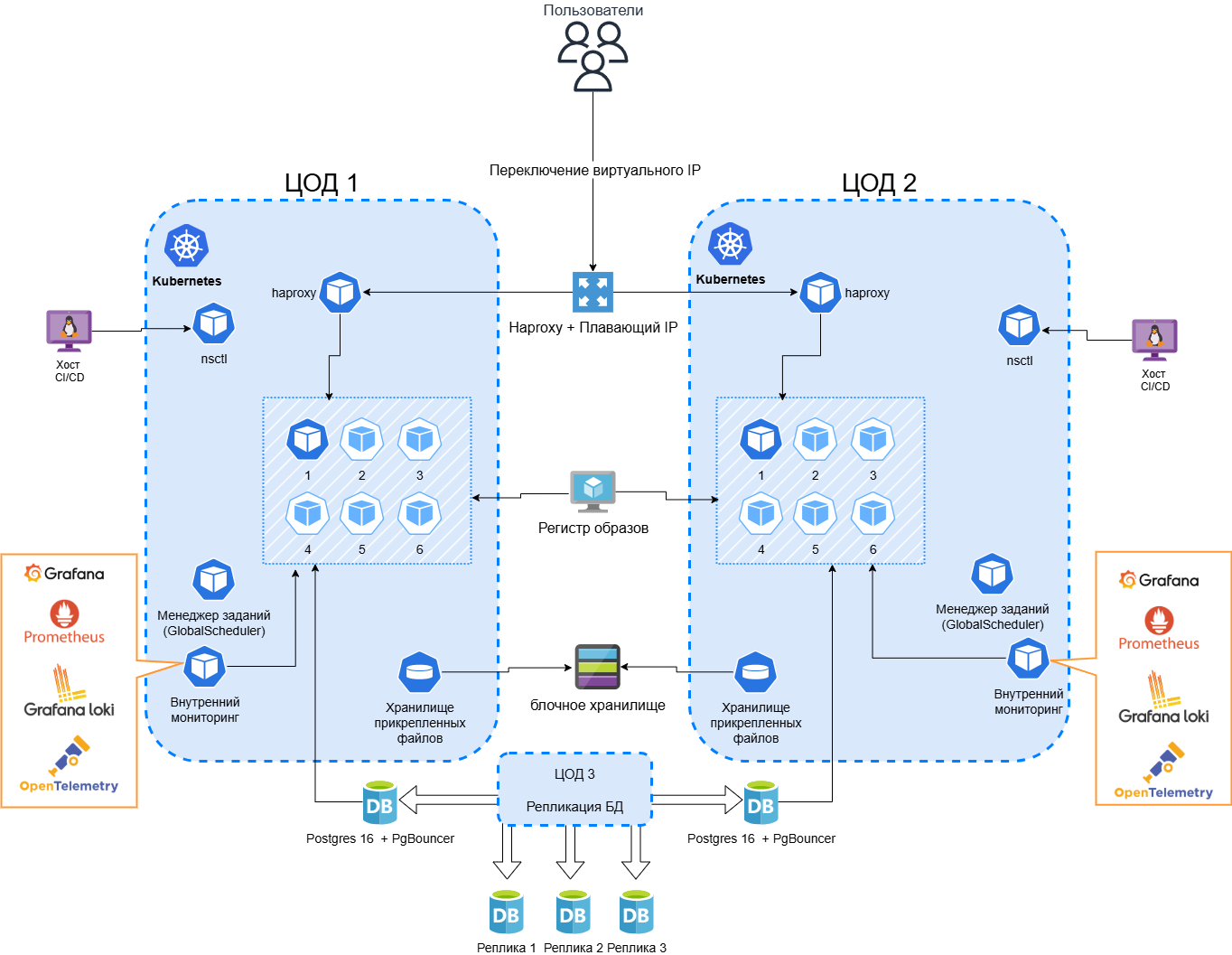
Вариант DR Active–Active#
Два кластера Kubernetes. Внутри каждого кластера используется gsroute - JGroups Gossip Router - который обеспечивает маршрутизацию кластерных групп.
Публикация на IP: сервис gsroute должен быть опубликован на выделенный IP; допускается публикация на том же узле и IP, где сам роутер, при соблюдении сетевых правил (firewall, ACL).
«Резиновый» кластер. Имеем несколько control-host и worker-нод, разнесённых по разным ЦОДам. Кластер подстраивается под текущую нагрузку: при падении части площадки горизонтально растёт за счёт других узлов.
Балансировка: трафик между ЦОДами распределяется HAProxy.
Если один ЦОД падает, пользователи, чьи сессии были закреплены за ним, получают разрыв соединения, после чего им необходимо заново авторизоваться в системе.
Пользователи, чьи сессии обслуживает живой ЦОД, ничего не делают и продолжают работу.
Нагрузка на оставшийся ЦОД возрастает, поэтому необходим резерв ресурсов.
Модель Active–Active используется в тех случаях, когда нагрузка заранее распределяется между двумя площадками, а каждая площадка способна принять на себя дополнительную долю трафика в случае отказа другой. Преимущество подхода состоит в том, что отказ одной площадки не требует полноценного холодного старта резервного ЦОДа: трафик просто перераспределяется.
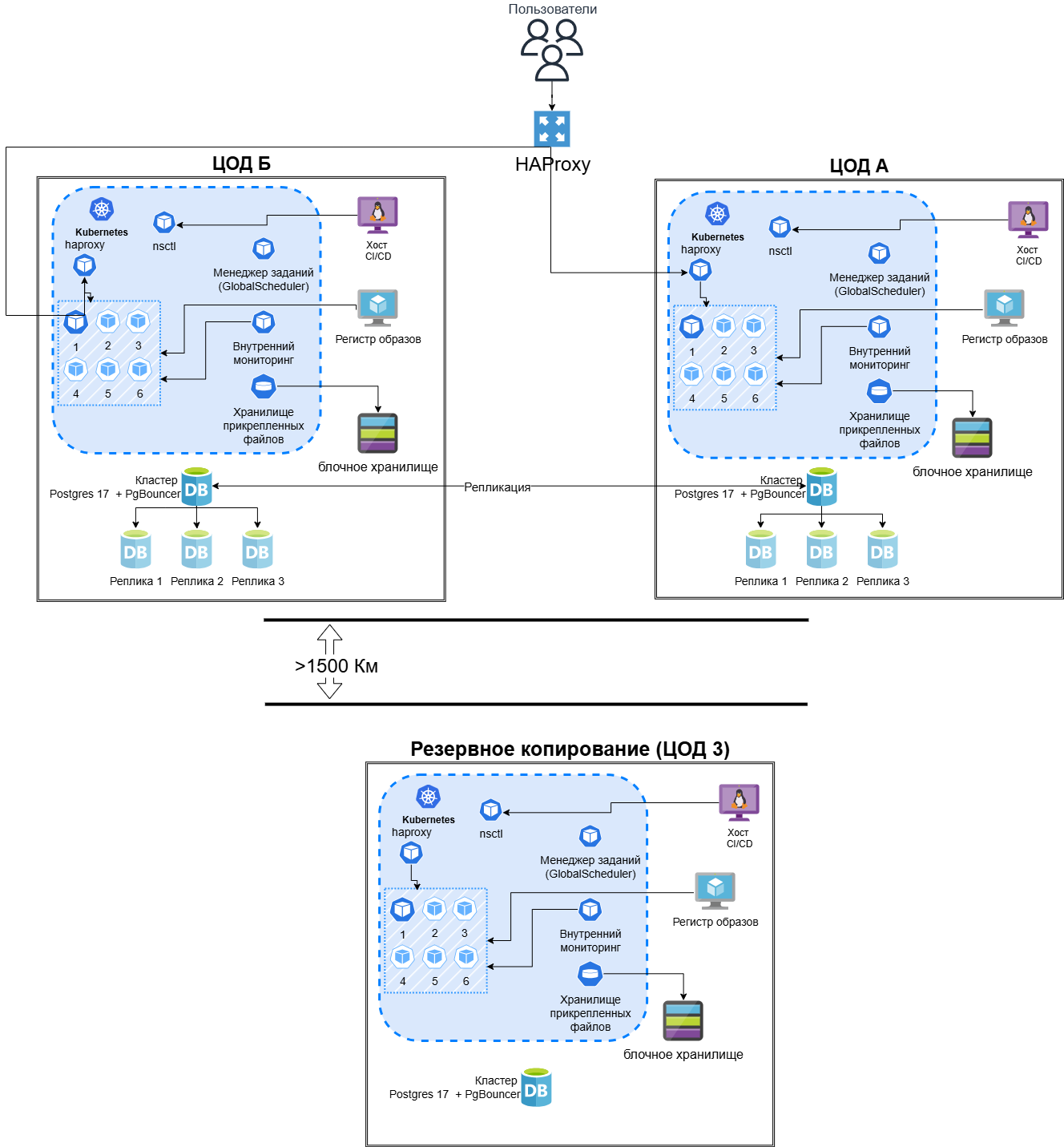
Гибридный вариант (два основных + третий резервный)#
В обоих основных (активная эксплуатация) ЦОДах проходят реплики.
В третьем резервном ЦОДе - хранятся бэкапы/реплики:
логический дамп,
бинарный дамп,
Конфигурационные файлы (K8S, приложения, LB, секреты в зашифрованном виде).
Регламент: резервный ЦОД должен быть поднят за несколько часов (RTO).
Гибридная модель сочетает активную работу двух основных площадок или основной и резервной площадки с третьей выделенной площадкой хранения резервных копий и реплик. Третий ЦОД не обязательно обслуживает пользователей в штатном режиме, но должен быть способен принять восстановление в заранее определённое время.
Требования к ключевым компонентам#
Kubernetes#
Kubernetes является базой вычислительного слоя Global ERP, поэтому отказоустойчивость платформы напрямую зависит от конфигурации кластера. Для HA-сценариев используется конфигурация с несколькими control-plane узлами и кворумом etcd. Узлы control-plane размещаются с учётом отказоустойчивости: по разным стойкам, сегментам и, если это допускается сетевой задержкой, по разным площадкам. Worker-узлы имеют резерв по ресурсам, чтобы выдерживать потерю одной или нескольких нод без остановки бизнес-критичных подов.
Кластер Kubernetes поддерживает автоматическое восстановление прикладных функций при сбоях аппаратных средств отдельных узлов. Kubernetes постоянно сопоставляет фактическое состояние кластера с заданным состоянием и восстанавливает поды, сервисы и маршрутизацию при отклонениях. Если узел становится недоступен из-за аппаратной ошибки, перезагрузки или отказа ОС, рабочая нагрузка перераспределяется на доступные worker-узлы при наличии свободных ресурсов.
Kubernetes также восстанавливает прикладные функции при ошибках, связанных с программным обеспечением: аварийном завершении контейнера, зависании процесса, ошибке запуска пода или недоступности прикладного экземпляра. Для этого используются механизмы контроля состояния подов, автоматического перезапуска контейнеров, пересоздания подов и возврата к заданному состоянию Deployment.
Если программный сбой затрагивает отдельный экземпляр приложения, Kubernetes исключает неработающий под из обслуживания и восстанавливает его в соответствии с текущей конфигурацией. При наличии нескольких реплик нагрузка продолжает обслуживаться доступными экземплярами Global ERP, а балансировщик и проверки доступности направляют пользовательский трафик только на работоспособные компоненты.
Сохранность данных при таких сбоях обеспечивается использованием внешних постоянных хранилищ и механизмами PostgreSQL, включая WAL и восстановление согласованного состояния после аварийного завершения работы.
В составе HA-конфигурации Kubernetes учитываются следующие элементы:
control-plane узлы — обеспечивают управление кластером и поддержание заданного состояния;
worker-узлы — выполняют прикладные поды Global ERP и принимают перераспределённую нагрузку при отказах;
etcd — хранит состояние Kubernetes-кластера. В конфигурациях с отдельным кластером etcd приоритет отдаётся скорости чтения и записи, поэтому используются твердотельные накопители;
манифесты и параметры развёртывания — cluster-scoped и namespace-scoped манифесты, секреты в зашифрованном виде, Helm-values и другие параметры сохраняются отдельно, чтобы восстановление кластера было воспроизводимым.
Load Balancer#
Балансировщик нагрузки должен обеспечивать не только распределение трафика, но и участвовать в сценариях отказоустойчивости. Для этого нужны активные health-checks, корректные тайм-ауты, механизм временного вывода узлов из пула при релизе или аварии и согласованная стратегия маршрутизации сессий.
Горячее обновление по модулям: LB отключает отдельные модули, блокирует их на время релиза, затем возвращает в пул.
Стратегии балансировки:
roundrobin (по очереди),
leastconn (наименьшее число активных сессий - приоритет отдачи сессий: «где меньше, туда новые»),
source/ip-hash (по IP).
Health-checks: активные проверки с тайм-аутами и интервалами.
Интеграция с CI/CD: скрипты для проверки статуса перед/после релиза.
Сеть (CNI + внешняя надёжность)#
Сетевая политика похожа на правила брандмауэра или группы безопасности, которые позволяют определить допустимый входящий и исходящий трафик. В состав основных сетевых API-интерфейсов Kubernetes входит NetworkPolicy API.
Внешняя надёжность сети: пограничный роутер с firewall, чёткие ACL.
Хранилище и управление дампами#
Эфемерные хранилища - это непостоянные тома, живущие в рамках жизненного цикла пода. Они исчезают при пересоздании пода и не подходят для хранения постоянных данных. Состояние не хранится на таких томах. Любая инфраструктура разворачивается по системным требованиям заново, компоненты идемпотентно доставляются и конфигурируются.
Дампы памяти JVM: предусмотрена возможность снимать heap дампы с приложений:
В под добавляется дополнительный «транспортный» контейнер для безопасной передачи дампов.
Размер ноды: не рекомендуем >32 ГБ RAM на ноду, для того чтобы дампы были переносимыми по сети/дискам.
Хранилище для дампов: резервируем отдельное место (quota). Также необходимо настроить политики ротации.
Файловое хранилище (NFS) должно рассматриваться как самостоятельный отказоустойчивый компонент, а не как вспомогательный сервис. Потеря доступа к NFS может приводить к полной остановке приложения, если на нём размещены конфигурации, пользовательские файлы, временные каталоги или логически значимые данные.
Для PROD необходимо предусматривать резервный NFS-сервер либо иной эквивалентный механизм хранения с возможностью переключения. Между основной и резервной сторонами должна поддерживаться синхронизация, а сама процедура смены активного файлового узла должна быть описана в runbook и регулярно проверяться в тестовом контуре.
Мониторинг - метрики#
Kubernetes/узлы: CPU/Memory/Load/IOPS, диск/inode, network tx/rx, taints, частота рестартов.
Поды/приложения: ошибки 5xx/4xx, очереди, размер пулов соединений, количество открытых файлов, JVM memory.
LB HAProxy: статус бэкендов, активные/ожидающие сессии, ошибки health-check.
PostgreSQL: логи, количество подключений.
Бэкапы: наличие свежих архивов, размер, checksum, длительность, статусы.
Сеть: packet loss между ЦОДами, ошибки интерфейсов, пропускная способность каналов.
Хранилище/CSI: состояние пулов.
PostgreSQL - репликации и кластерные решения#
Контроль целостности данных на уровне СУБД обеспечивается механизмами PostgreSQL:
транзакционной моделью ACID;
журналом предзаписи WAL;
ограничениями схемы данных;
блокировками и механизмами восстановления после сбоев.
Транзакции фиксируют изменения атомарно, а при аварийном завершении незавершённые операции откатываются, после чего СУБД восстанавливает согласованное состояние по последнему зафиксированному коммиту.
Дополнительный уровень защиты обеспечивают репликация, резервное копирование, WAL-архивирование и регулярная проверка восстановления. Эти механизмы позволяют контролировать согласованность данных не только в штатной работе, но и при отказах, переключении на реплику или восстановлении из резервной копии.
СУБД является наиболее критичным компонентом с точки зрения целостности данных, поэтому для PROD-среды необходимо использовать primary–standby схему с репликацией. Для межплощадочного DR-контурa предпочтительна асинхронная репликация: она снижает влияние сетевой задержки на транзакции, но требует осознанного принятия небольшого RPO. Синхронная репликация допустима только в пределах стабильной и низколатентной сети.
PostgreSQL поддерживает кластерные схемы эксплуатации СУБД на базе primary–standby архитектуры, потоковой репликации и механизмов переключения роли основного узла. В такой конфигурации один сервер выполняет роль primary, а один или несколько серверов работают как standby-реплики и получают изменения из основного узла.
Кластеризация серверов СУБД используется для повышения доступности, снижения времени восстановления и подготовки сценариев переключения при отказе основного узла. В зависимости от требований к RTO и RPO применяются синхронная или асинхронная репликация, локальные и удалённые реплики, а также средства оркестрации отказа.
Для оркестрации отказа используются open-source решения (Pacemaker, Patroni) или коммерческие (Postgres Pro Cluster, BIHA, Tantor XData) - последние оправданы, если необходима вендорская поддержка.
Логические и бинарные дампы эффективны при размере базы до 1.5 ТБ; для баз большего объёма применяется только потоковая репликация и физические бекапы (pg_probackup с WAL-архивированием).
Для снижения нагрузки при восстановлении реплик применяется цикличная схема ротации: три (или пять) реплики включаются поочерёдно, каждая работает один день, затем выключается и уступает место следующей. Когда реплика включается повторно на четвёртый день, ей нужно синхронизировать лишь три дня изменений, а не всю базу целиком.
Репозиторий артефактов и CI/CD#
Недоступность CI/CD или Nexus-подобного репозитория не всегда означает немедленную аварию сервиса, но существенно осложняет восстановление и выпуск исправлений. Поэтому эти системы должны резервироваться, регулярно обновлять резервные копии и контролироваться с точки зрения доступности.
Минимальное требование - наличие резервной копии репозитория образов, исходного кода, пайплайнов и конфигураций развертывания. Для зрелого DR-контура желательно обеспечить удалённую реплику и на стороне CI/CD.
Стратегии деплоя#
Выбор стратегии обновления приложения - это баланс между скоростью вывода изменений, надёжностью и стоимостью инфраструктуры. Конкретный выбор зависит от допустимого простоя, критичности сервиса, бюджета и зрелости процессов отката.
Recreate полностью останавливает старую версию перед запуском новой. Это самый простой и дешёвый вариант, но он гарантирует простой в момент деплоя. Оправдан на ранних этапах проекта и во внутренних системах с плановыми окнами обслуживания.
Rolling Update обновляет инстансы по одному: каждый выводится из-под нагрузки, обновляется, проверяется и возвращается в работу. Простоя нет - в пуле всегда остаются работающие инстансы. Некоторое время параллельно работают две версии приложения, что усложняет анализ поведения. Хорошо ложится на Kubernetes и подходит для большинства сервисов с требованием высокой доступности.
Blue/Green держит два полноценных окружения: «синее» (текущий прод) и «зелёное» (новая версия). После тестирования «зелёного» трафик переключается мгновенно; откат - переключить обратно. Простоя нет, откат молниеносный, но требует двойных ресурсов. Оправдан для критичных сервисов с жёстким SLA при наличии соответствующего бюджета.
Canary выкатывает новую версию постепенно: сначала на 2% пользователей, затем на 10%, 25%, 75% и наконец 100%. Риск инцидента ограничен малой группой; при проблемах выполняется откат. Требует развитой системы метрик и грамотной маршрутизации трафика. Идеален для крупных пользовательских систем и релизов с труднопредсказуемыми последствиями.
Shadow разворачивает новую версию в отдельном кластере и зеркалирует на неё реальный трафик, но не отвечает пользователям. Позволяет тестировать на боевой нагрузке без какого-либо влияния на пользователей. Стоит дорого и требует сложной маршрутизации. Применяется для высокорисковых изменений в ядре системы.
Резервное копирование и верификация#
Состав резервируемых компонентов#
В резервный контур Global ERP включаются не только данные PostgreSQL, но и все компоненты, необходимые для восстановления работоспособного экземпляра системы: база данных, файловые хранилища, релизные пакеты, образы контейнеров и конфигурация Kubernetes.
Резервирование БД выполняется средствами PostgreSQL / Postgres Pro. В зависимости от размера базы и требований к восстановлению используются логические дампы, физические резервные копии, WAL-архивирование, PITR, потоковая репликация и реплики в рамках одного или нескольких ЦОД.
Файловые хранилища резервируются как самостоятельный компонент системы. В резервную копию включаются пользовательские файлы, прикреплённые документы, каталоги хранения комплектов, временно значимые файлы и иные данные, размещённые вне БД. Для NFS или аналогичного хранилища используется синхронизация с резервным узлом либо резервное копирование средствами файловой системы или инфраструктурной платформы.
Релизные пакеты и артефакты развёртывания сохраняются отдельно от продуктивных экземпляров системы. В состав резервной копии входят дистрибутив сервера приложений, прикладные библиотеки, комплекты appkit и groupkit, образы контейнеров, Helm-чарты, Helm-values, скрипты установки и обновления.
Конфигурация Kubernetes также входит в резервный контур. Сохраняются namespace-scoped и cluster-scoped манифесты, параметры развёртывания, конфигурации сервисов, Ingress, ConfigMap, Secret в зашифрованном виде, настройки балансировки и параметры подключения к внешним сервисам. Такой состав резервирования позволяет восстановить не только данные, но и воспроизводимую конфигурацию инфраструктуры.
Регламент backup/restore#
В Global ERP применяется документированный регламент резервного копирования и восстановления. Регламент описывает состав резервируемых компонентов, периодичность операций, порядок создания резервных копий, правила хранения архивов, проверку контрольных сумм, тестовое восстановление и порядок действий при восстановлении после отказа.
Для базы данных регламент backup/restore описан в отдельной статье: Резервное копирование и восстановление БД. В ней приведены сценарии снятия дампа, архивирования, переноса во внешнее хранилище, восстановления дампа, сброса настроек шедулера и отключения интеграций при разворачивании копии на другом контуре.
Для инфраструктурных компонентов регламентируется резервирование файловых хранилищ, релизных пакетов, образов контейнеров, Helm-values, манифестов Kubernetes, ConfigMap и Secret в зашифрованном виде. Порядок восстановления этих компонентов фиксируется в runbook-документах и проверяется в рамках тестовых восстановлений.
Jump Host и доступ#
Все подключения к продуктивной инфраструктуре осуществляются через Jump Host по SSH с ProxyJump - прямых входов в прод нет. Используются сертификаты. Все сессии логируются: команды и tty-вывод. Доступ разграничен по окружениям и ролям.
Верификация бекапов#
Наличие свежих архивов, их размер и контрольные суммы проверяются автоматически при каждом создании. Периодически выполняется test restore в изолированную песочницу. Мониторинг отслеживает время последней успешной верификации и сигнализирует при её отсутствии.
Автотест в CI#
После любого restore автоматически запускается CI-job: поднимается тестовый стенд, выполняются миграции, прогоняются SQL и HTTP smoke-тесты, собирается отчёт (JUnit/Allure) и публикуется результат. Инструмент - JEXL-скрипт проверок.
Test Restore#
Пре‑чек ресурсов: вычислить потребности CPU/RAM/дисков под восстановление; проверить, что конфиг СУБД корректен.
Процедура: развернуть дамп / включить реплику как master. Поднять сервисы.
Проверки: скрипты для smoke‑тестов.
Артефакты: сохранить логи, графики, скорость восстановления.
Откат изменений#
Откат изменений не является аварийным восстановлением в строгом смысле, но напрямую влияет на устойчивость эксплуатации. Если новая версия приложения вызывает критический дефект, откат Helm-релиза должен выполняться как штатная и многократно проверенная операция. При этом важно заранее понимать совместимость схемы БД с предыдущей версией приложения.
Ошибочные изменения базы данных требуют отдельного подхода. Если существует резервная копия до момента изменений, применяется Point-in-Time Recovery. Если изменение обратимо, предпочтителен заранее подготовленный downgrade-скрипт. Откатывать схему БД без проверенного сценария нельзя, поскольку такой откат сам по себе может стать причиной полноценного инцидента.
Конфигурационные ошибки - неверный Secret, ConfigMap или переменная среды - должны устраняться через возврат предыдущей версии из Git или из истории изменений Kubernetes. Важно, чтобы история таких изменений хранилась централизованно и позволяла восстановить точное рабочее состояние.
Сценарии восстановления#
Простые отказы (зелёная тревога)#
Простые отказы в большинстве случаев обрабатываются автоматически: отказоустойчивые механизмы платформы самостоятельно перераспределяют нагрузку, уведомления поступают администраторам по системе мониторинга.
Отказ одного или нескольких worker-узлов Kubernetes. Kubernetes автоматически перераспределяет поды на работающие узлы. Кластер Global ERP продолжает обслуживать запросы. Администратор проверяет статус и анализирует причину сбоя.
Целевое RTO - менее 10 минут.
Отказ мастер-реплики PostgreSQL. Дежурный администратор запускает процедуру смены ролей. Порядок действий:
остановить поды Global ERP (или масштабировать Deployment до 0 реплик);
выполнить промоутинг реплики;
проверить доступность и целостность данных;
обновить параметры подключения;
запустить поды и проверить логи. При сбое репликации выполняется восстановление из последней полной резервной копии с ручным восстановлением кластера.
Целевое RTO - 45 минут.
Отказы средней значимости (жёлтая тревога)#
Отказ NFS-сервера. При потере доступа к файловому хранилищу кластер Global ERP прекращает отвечать на запросы. Администратор активирует резервный NFS-сервер, убеждается в синхронизации данных и обновляет параметры, после чего перезапускает поды. Целевое RTO - 35 минут.
Полный отказ кластера приложений Global ERP. При наличии синхронизированного резервного кластера администратор выполняет переключение на него. Если такой кластер не готов - выполняется стандартная процедура установки релиза или разворачивания кластера серверов приложений с нуля. Целевое RTO - 4 часа.
Полный отказ кластера PostgreSQL. На одном из узлов восстанавливается последняя полная резервная копия, применяются WAL-журналы для Point-in-Time Recovery до максимально актуальной точки. После проверки данных, индексов и логической целостности обновляются конфигурации подключения приложений и перезапускаются интеграционные сервисы. Целевое RTO - 6 часов.
Полный отказ кластера Kubernetes. Системный администратор совместно с инженером DevOps принимают решение о переустановке. После переустановки кластера выполняется переключение на резервный кластер или стандартная процедура развёртывания. Целевое RTO - 5 часов.
Катастрофические отказы (красная тревога)#
Полный отказ ЦОД. После получения от администратора прогноза длительной недоступности и согласования выполняется активация инфраструктуры в резервном ЦОД. Последовательность:
остановить экземпляр Global ERP в основном ЦОД;
остановить потоковую репликацию WAL-логов;
промоутировать удалённую реплику на сервере резервного ЦОД;
обновить DNS-запись A на адрес шлюза в резервном ЦОД;
активировать резервный кластер Kubernetes, настроенный на новый мастер БД и локальный NFS;
проверить доступность системы по новому адресу; восстановить интеграции.
Целевое RTO - 60 минут для самого переключения.
Аварийное восстановление без Kubernetes. Применяется при полной недоступности инфраструктуры Kubernetes. Порядок:
авторизоваться под сервисной учётной запись;
восстановить БД из последней полной резервной копии PostgreSQL с применением WAL-журналов;
распаковать актуальные версии ПО сервера и пользовательских библиотек;
запустить сервер Global ERP;
запросить и применить лицензию на экземпляре;
выполнить нагон релиза для синхронизации схемы БД с версией приложения.
Тестирование процедур аварийного восстановления#
Наличие DR-документа без регулярного тестирования не даёт реальной гарантии готовности. Поэтому тестирование должно быть обязательной частью эксплуатации. Практически это означает следующее.
Не реже одного раза в год следует проводить тест потери worker-узла Kubernetes. Цель - убедиться, что поды действительно перераспределяются, а приложение остаётся доступным в пределах целевого RTO.
Не реже одного раза в квартал следует отрабатывать переключение PostgreSQL на реплику.
Не реже одного раза в год следует выполнять тест резервного NFS. Здесь важно проверять не только доступность хранилища, но и корректность прав, целостность файлов и способность приложения читать и записывать данные после смены активного узла.
Не реже одного раза в год следует проводить полное восстановление тестового экземпляра из резервной копии.
Не реже одного раза в год следует проводить учение по переключению в удалённый ЦОД. Такой тест должен включать не только запуск инфраструктуры, но и проверку конечной доступности системы, а также пост-анализ фактических значений RTO и RPO.
По результатам каждого теста необходимо фиксировать:
фактическое время восстановления;
фактический объём потери данных;
узкие места в процедурах;
проблемы в документации;
необходимые изменения в инфраструктуре, автоматизации или регламентах.
Рекомендации по оформлению runbook и DRP#
Для практической эксплуатации рекомендуется создать набор отдельных runbook-документов. В каждый runbook разумно включать:
условие запуска сценария;
признаки, по которым сценарий подтверждается;
список ответственных ролей;
точную последовательность действий;
критерии успешного завершения;
порядок возврата в штатный режим;
ссылки на команды, скрипты и шаблоны конфигурации.
Такой подход позволяет оставить основной документ архитектурным и управленческим, а низкоуровневые команды - вынести в отдельные эксплуатационные инструкции.
Примерный список необходимых runbook-документов:
переключение PostgreSQL на локальную реплику;
переключение PostgreSQL на удалённую реплику в резервном ЦОДе;
восстановление PostgreSQL из резервной копии;
активация резервного NFS и возврат на основной сервер;
переустановка Kubernetes-кластера и восстановление конфигурации;
переключение пользовательского трафика и изменение DNS;
полное переключение в резервный ЦОД;
аварийный запуск Global ERP без Kubernetes;
регламент резервного копирования и восстановления компонентов Global ERP.