Kubernetes: телеметрия кластера#
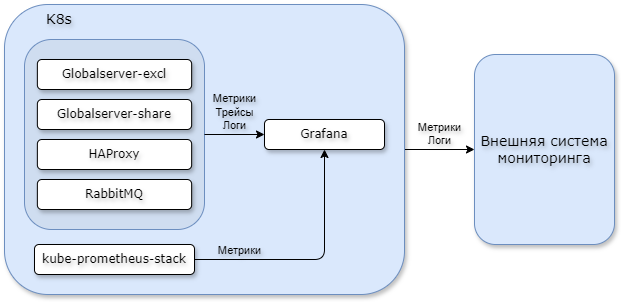
Кластер Global ERP собирает следующую телеметрию:
Метрики с использованием стека kube-prometheus-stack + OpenTelemetry SDK + Alloy + VictoriaMetrics.
Трейсы пользовательских операций с использованием стека OpenTelemetry SDK + Alloy + Tempo.
Логи с использованием стека Alloy (Promtail) + Loki.
Профили сервера приложений с использованием стека Alloy + Pyroscope.
Кластер Global ERP поддерживает интеграцию с дополнительными средствами мониторинга и диагностики: PPEM, Zabbix, Prometheus и VictoriaMetrics. Встроенный контур телеметрии используется для оперативного мониторинга, а внешние системы подключаются для долгосрочного хранения, централизованного наблюдения, анализа состояния инфраструктуры и контроля СУБД.
Вся телеметрия собирается во внутренние инстансы VictoriaMetrics, Loki, Tempo и Pyroscope, которые запущены в поде grafana. Внутренняя Grafana используется для оперативного мониторинга системы, так как данные удаляются при перезапуске пода.
Для долгосрочного хранения телеметрии требуется отдельная внешняя система мониторинга.
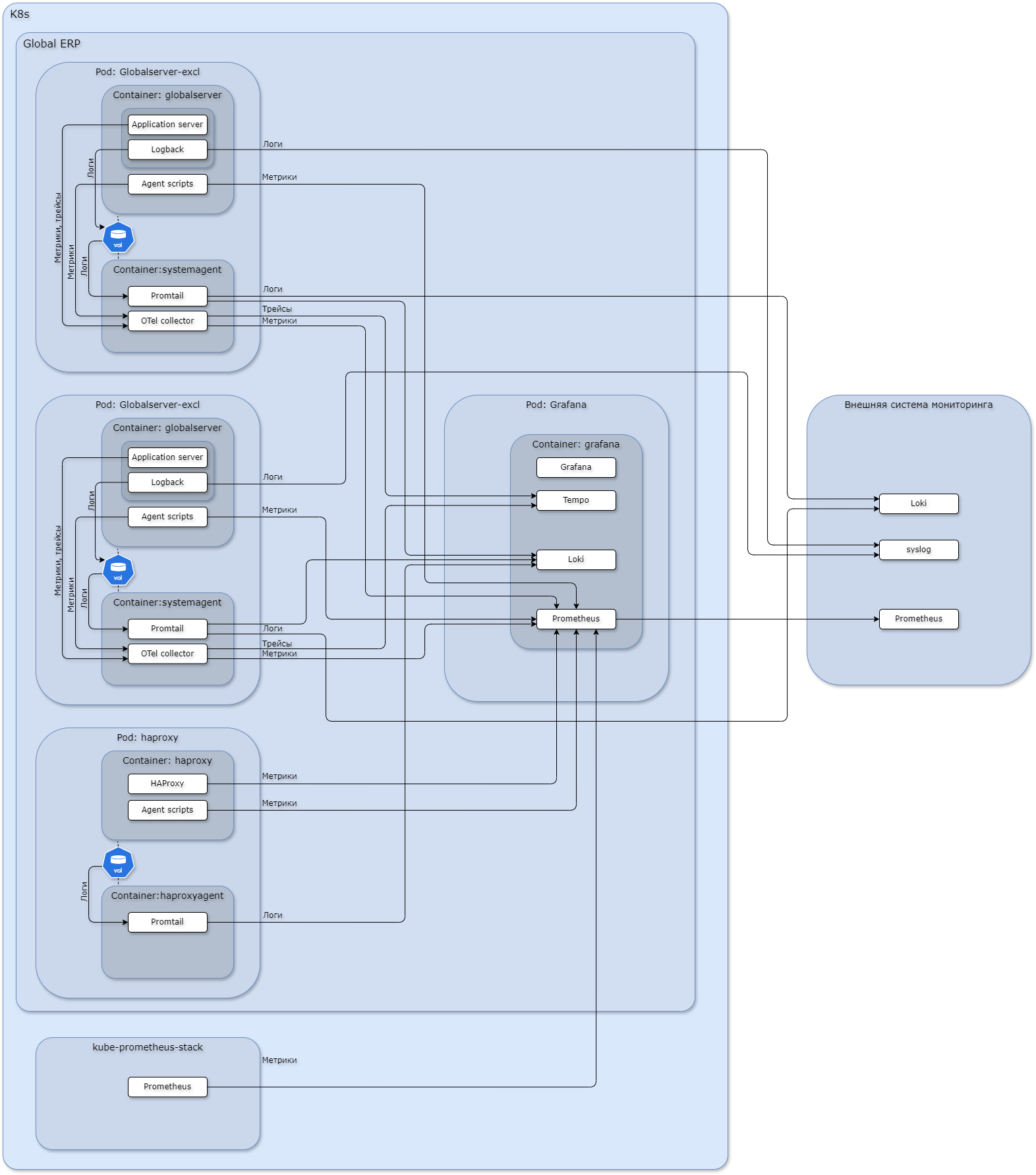
Логи#
Логи планировщика заданий и серверов Global обрабатываются агентом Alloy и отсылаются в базу Loki. Логи HAProxy и обходчика очередей обрабатываются агентом Promtail и отсылаются в базу Loki.
Также возможно настроить отправку логов во внешний инстанс Loki или отправку логов напрямую из Logback Globalserver-a.
Внешний инстанс Loki#
Для отправки логов во внешний инстанс Loki при конфигурировании групп ресурсов и книг ресурсов кластера Global в поле «Дополнительно отсылать метрики во внешнюю систему» требуется выставить «Да» и задать корректный адрес внешнего инстанса Loki.
Loki устанавливается по официальной документации.
Простейший конфиг приведён ниже. При его использовании требуется задать корректные значения параметров path_prefix, chunks_directory и rules_directory.
Пример config.yaml
auth_enabled: false
server:
http_listen_port: 3100
grpc_listen_port: 9096
common:
instance_addr: 127.0.0.1
path_prefix: <path> #/mnt/data/loki
storage:
filesystem:
chunks_directory: <path> #/mnt/data/loki/chunks
rules_directory: <path> #/mnt/data/loki/rules
replication_factor: 1
ring:
kvstore:
store: inmemory
query_range:
results_cache:
cache:
embedded_cache:
enabled: true
max_size_mb: 100
schema_config:
configs:
- from: 2020-10-24
store: tsdb
object_store: filesystem
schema: v13
index:
prefix: index_
period: 24h
ruler:
alertmanager_url: http://localhost:9093
analytics:
reporting_enabled: false
Отправка логов из Logback#
Для отправки логов во внешнюю систему напрямую из Logback Globalserver-а в профиль аппкита по пути profile\globalserver\template\config требуется добавить дополнительные файлы конфигурации:
logback-LoggerContext-ext.xml- дополнительная конфигурация логгера «system».logback-LoggerContext-session-ext.xml- дополнительная конфигурация логгеров «app» и «session».
Метрики#
Телеметрия GlobalServer-а через агент Alloy отправляется во внутренний инстанс VictoriaMetrics.
Системная телеметрия кластера k8s собирается с помощью kube-prometheus-stack (требует отдельной установки).
Список собираемых метрик вынесен в отдельную страницу Kubernetes: метрики кластера.
Также возможно настроить внешний инстанс TSDB (Prometheus или VictoriaMetrics) на получение метрик из внутреннего инстанса VictoriaMetrics по «pull модели» либо настроить отправку метрик во внешнюю TSDB по «push модели».
kube-prometheus-stack в собственном кластере k8s#
При разворачивании кластера Global ERP в собственном кластере k8s требуется установить kube-prometheus-stack по официальной документации
kube-prometheus-stack в VK Cloud#
При разворачивании кластера Global ERP в VK Cloud требуется установить аддон «kube-prometheus-stack» из панели управления кластером. В конфигурации аддона для компонента prometheus-node-exporter требуется добавить блок «extraArgs» для получения телеметрии ФС нод кластера.
prometheus-node-exporter:
image:
repository: "prometheus/node-exporter"
tag: v1.7.0
namespaceOverride: "monitoring"
resources:
limits:
cpu: 200m
memory: 50Mi
requests:
cpu: 100m
memory: 30Mi
extraArgs:
- --collector.filesystem
- --collector.filesystem.mount-points-exclude=^/(dev|proc|sys|var/lib/docker/.+|var/lib/kubelet/.+)($|/)
- --collector.filesystem.fs-types-exclude=^(autofs|binfmt_misc|bpf|cgroup2?|configfs|debugfs|devpts|devtmpfs|fusectl|hugetlbfs|iso9660|mqueue|nsfs|overlay|proc|procfs|pstore|rpc_pipefs|securityfs|selinuxfs|squashfs|sysfs|tracefs)$
Настройка внешнего Prometheus для получения метрик по pull-модели#
Prometheus устанавливается по официальной документации. Для получения метрик сервера Global Prometheus настраивается на сбор метрик с внутреннего инстанса через федерацию.
Пример config.yaml
global:
scrape_interval: 5s
evaluation_interval: 5s
scrape_configs:
- job_name: 'federate'
scrape_interval: 15s
honor_labels: true
metrics_path: '/federate'
params:
'match[]':
- '{__name__=~"^[^go_].+"}'
static_configs:
- targets:
- '<prometheus_external_ip>:9090'
Настройка отправки метрик во внешнюю TSDB по push-модели#
Для отправки метрик во внешний инстанс Prometheus (VictoriaMetrics) при конфигурировании групп ресурсов и книг ресурсов кластера Global в поле «Дополнительно отсылать метрики во внешнюю систему» требуется выставить «Да» и задать корректный адрес внешнего инстанса TSDB.
Трейсы пользовательских операций#
Трейсы отображают стек и распределение времени вложенных вызовов при выполнении пользовательских операций.
Настройка отправки трейсов во внешний инстанс Tempo#
Для отправки трейсов во внешний инстанс Tempo при конфигурировании групп ресурсов и книг ресурсов кластера Global в поле «Дополнительно отсылать метрики во внешнюю систему» требуется выставить «Да» и задать корректный адрес внешнего инстанса Tempo.
Профили#
Профили - статистическая информация о потреблении функциями процессорного времени и памяти. Профили собираются агентом Alloy и отправляются во внутренний инстанс Pyroscope в поде grafana. Посмотреть профили можно в штатном интерфейсе Grafana «Основное меню» -> «Drilldown» -> «Profiles». Подробнее об использовании Pyroscope в главе Диагностика нагрузки