Диагностика нагрузки: дашборды, логи и Pyroscope#
Инструкция описывает порядок поиска проблемных участков в работе GlobalServer с использованием инструментов внутреннего мониторинга, журналов событий и профилирования во внутренней Grafana.
Документ применяется в случаях, когда в системе наблюдается аномальный рост нагрузки на ресурсы, не связанный с ожидаемой эксплуатационной активностью, выполнением плановых задач или работой интеграций.
Сценарий помогает последовательно:
определить наличие аномалии по метрикам;
найти наиболее нагруженные
pod’ы;проверить журналы событий;
выполнить профилирование потребления CPU и памяти;
зафиксировать результаты анализа для передачи разработчикам.
Общий порядок действий#
При выявлении резкого роста утилизации ресурсов анализ рекомендуется выполнять от общего уровня наблюдения к детальному:
открыть основные дашборды мониторинга;
определить период возникновения аномалии;
установить
pod’ы с наибольшей нагрузкой;проверить журналы проблемного
pod’а;перейти к профилированию CPU и RAM;
найти наиболее затратные участки через
Flame Graph;подготовить материалы для эскалации разработчикам.
Такой порядок позволяет сначала подтвердить сам факт проблемы, а затем постепенно сузить область поиска до конкретного процесса, функции, класса или модуля.
Выявление аномалии по дашбордам мониторинга#
Предположим, что администратор открывает панель мониторинга и обнаруживает резкий рост утилизации ресурсов. На графиках может наблюдаться неравномерное повышение сразу нескольких метрик.
Если такое поведение не связано с известной нагрузкой, плановыми задачами или интеграциями, существует высокая вероятность ошибки в коде либо некорректной работы прикладной логики.
Для первичного анализа рекомендуется использовать дашборды:
System Overview;VM Memory.
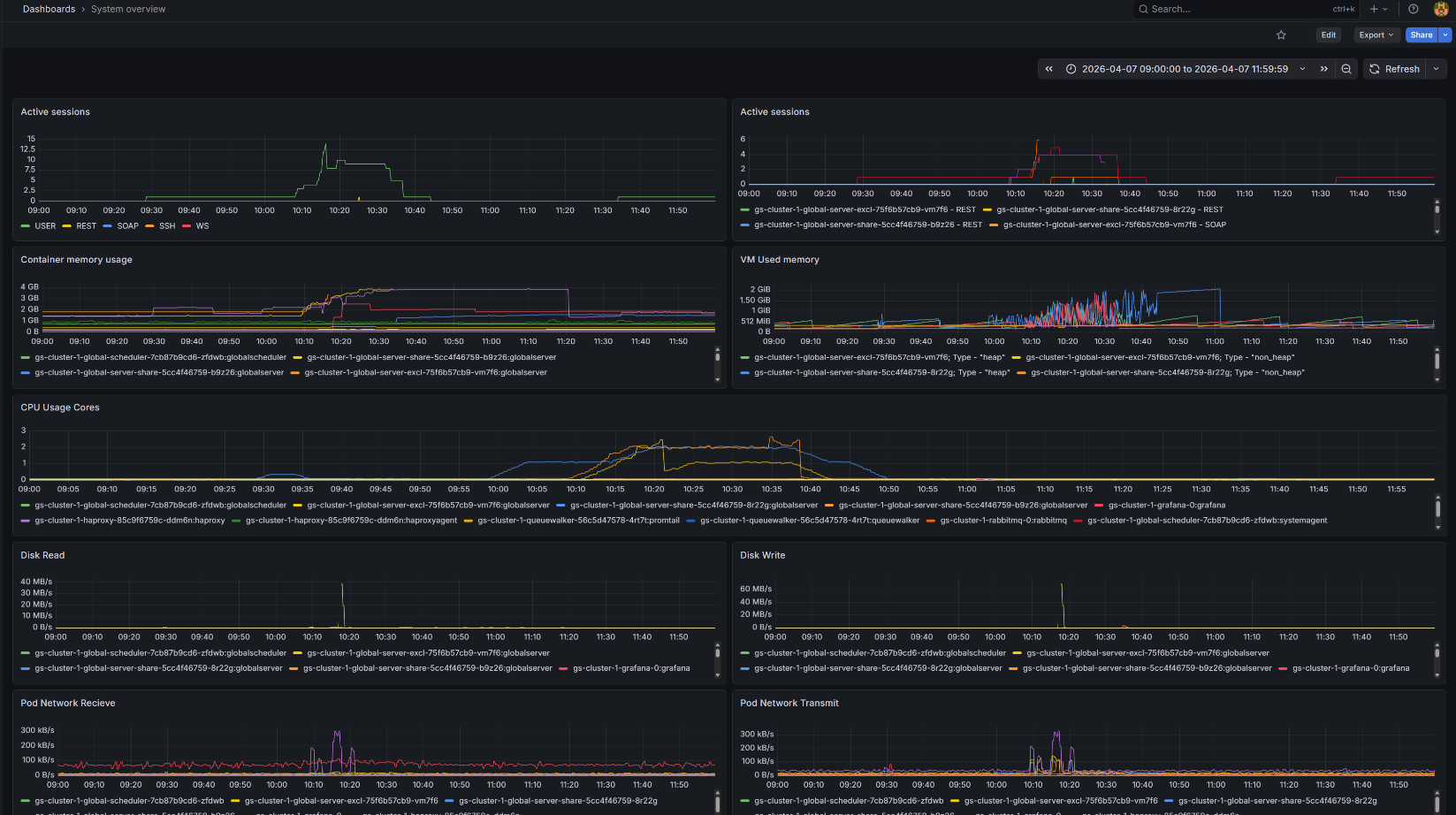
Рисунок 1. Дашборд System Overview
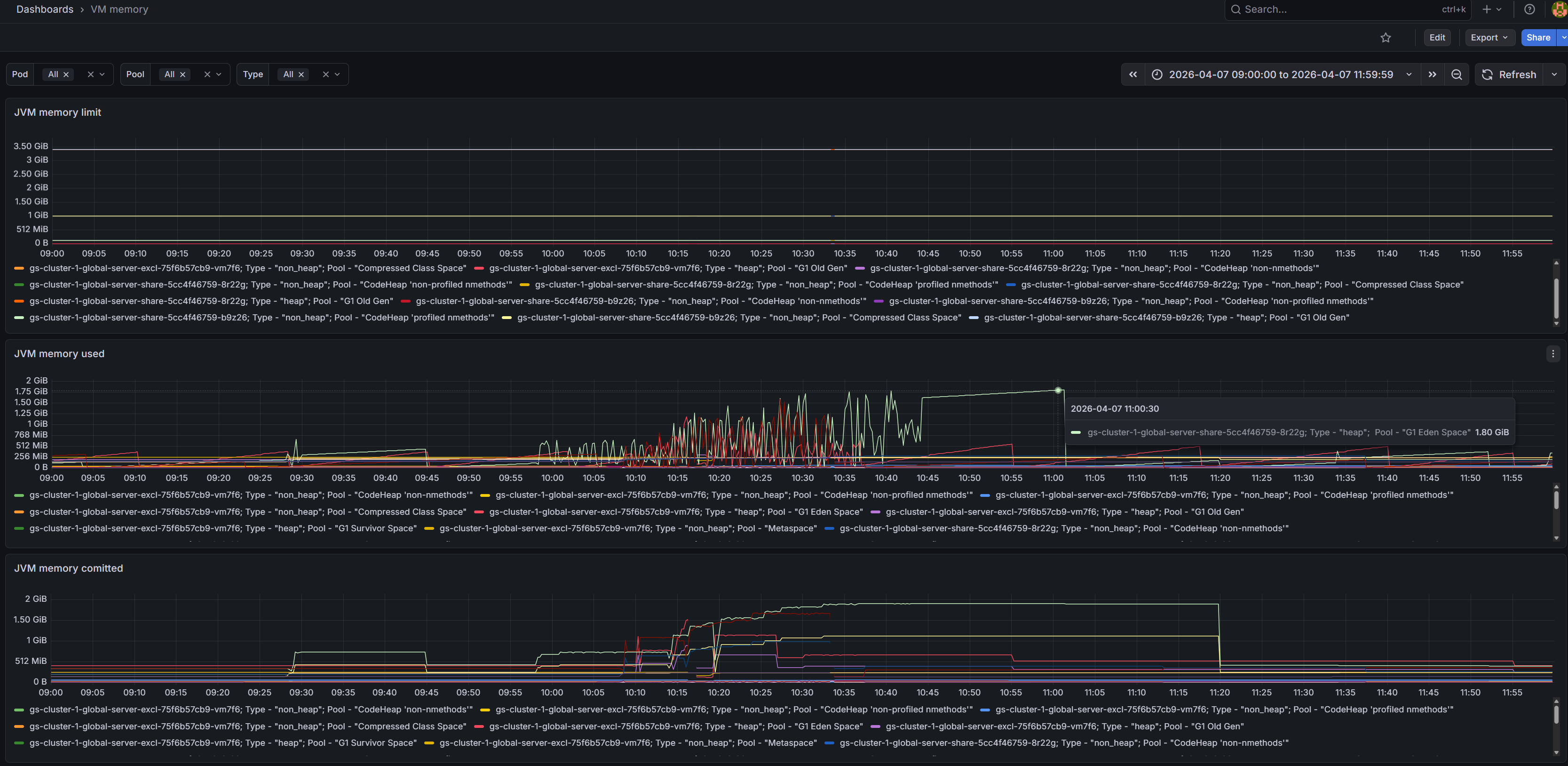
Рисунок 2. Дашборд VM Memory
При наведении курсора на график можно определить, к какому именно pod’у относится нагрузка.
По обоим дашбордам видно, что рост нагрузки затрагивает несколько pod’ов, однако наиболее высокая нагрузка наблюдается
на pod’е с окончанием -8r22g.
Анализ журналов#
После определения наиболее нагруженного pod’а необходимо перейти к дашборду Logs и настроить фильтрацию.
Рекомендуется указать:
проблемный
pod;временной интервал, соответствующий периоду роста нагрузки;
namespace, если это необходимо;дополнительные параметры поиска, если они помогают сузить выборку.
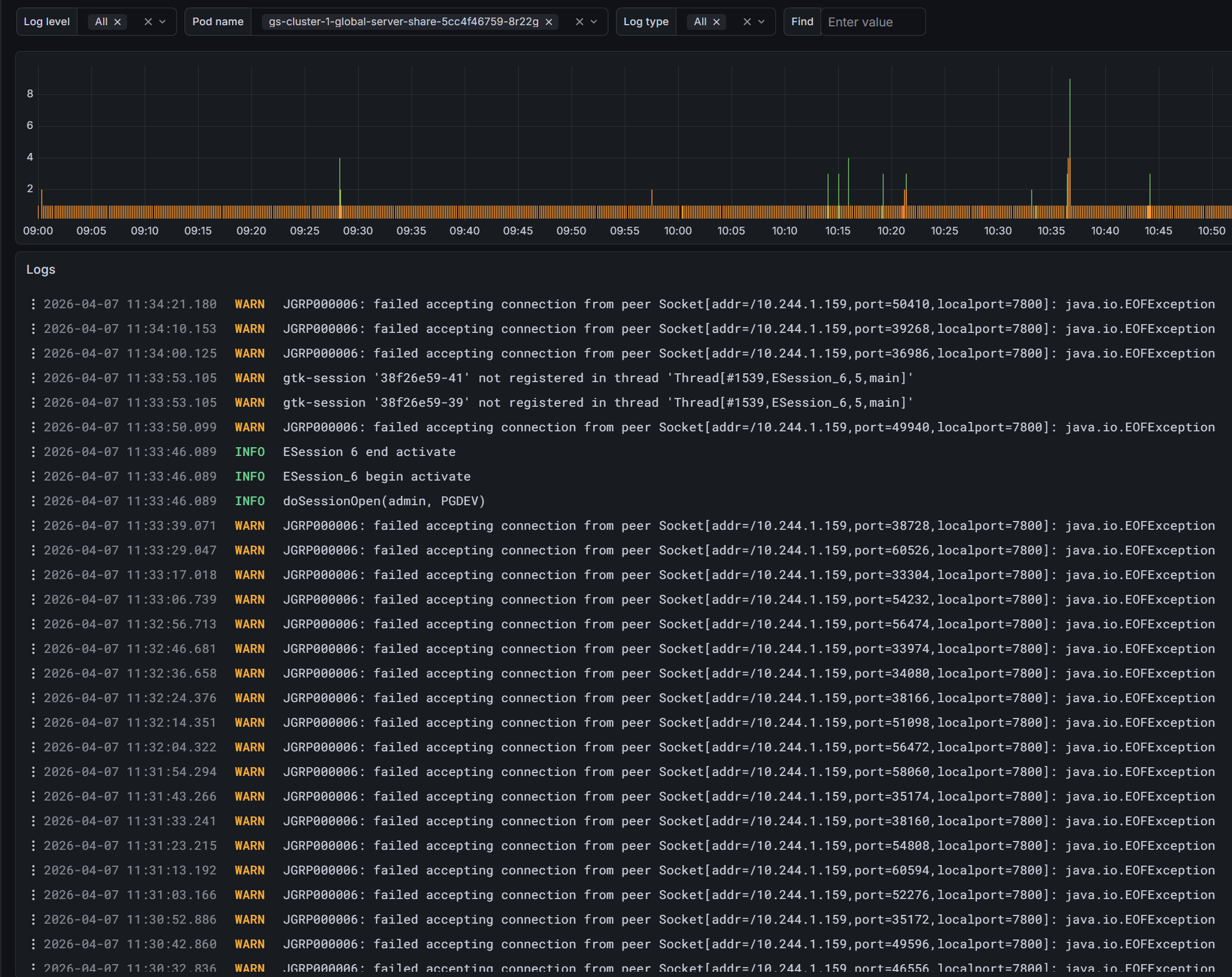
Рисунок 3. Анализ журнала проблемного pod’а
В рассматриваемом примере журналы не содержат явно выраженной диагностической информации, позволяющей однозначно установить причину проблемы.
Тем не менее по косвенным признакам можно сделать вывод, что источник повышенной нагрузки связан с работой GlobalServer.
Анализ проблемы с помощью профилирования#
Если анализ журналов не дал достаточного результата, необходимо перейти к инструментам профилирования:
Drilldown -> Profiles
В данном разделе доступны различные типы профилей и метрик.
Для первичного анализа рекомендуется открыть вкладку Labels, где можно:
выбрать
Profile Type;переключаться между профилями использования CPU и RAM;
фильтровать данные по конкретным
pod’ам.
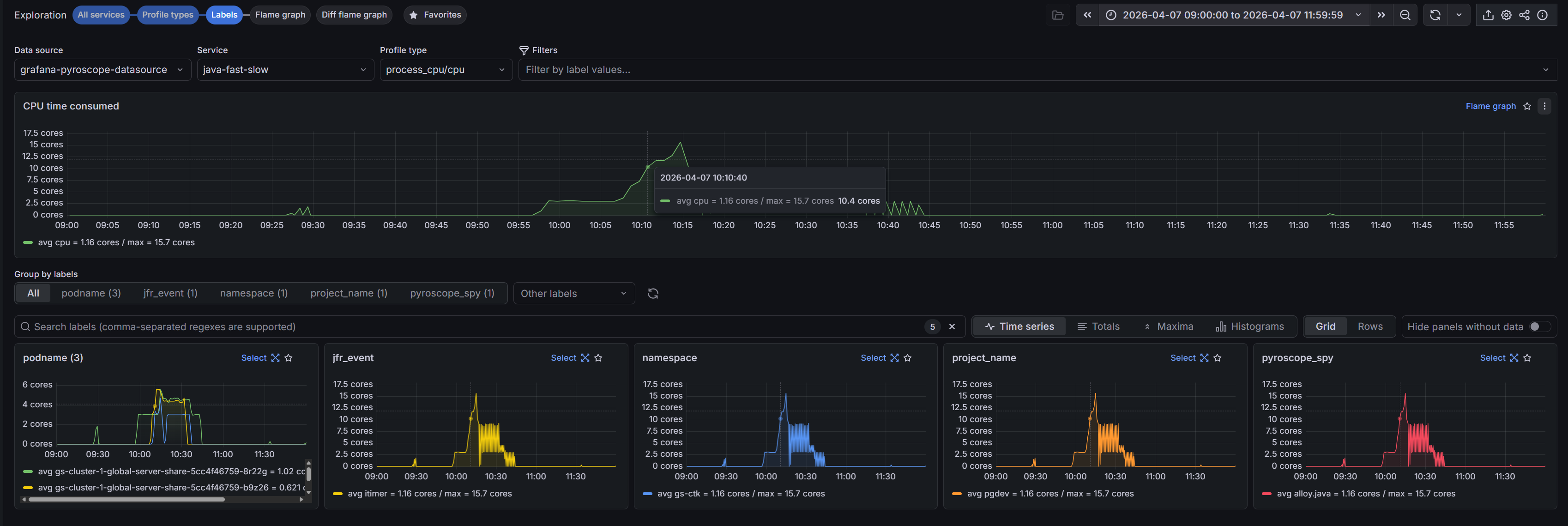
Рисунок 4. Анализ профилей на вкладке Labels
На данном этапе проблема подтверждается и на уровне профилирования: повышенная нагрузка сохраняется и воспроизводится в профилях.
Определение проблемного участка через Flame Graph#
Основным инструментом детального анализа является Flame Graph.
Для корректного анализа необходимо:
выбрать временной диапазон, соответствующий периоду аномальной нагрузки;
указать тип профиля: CPU или RAM;
выбрать проблемный
pod;отфильтровать участки с наибольшим потреблением ресурсов.
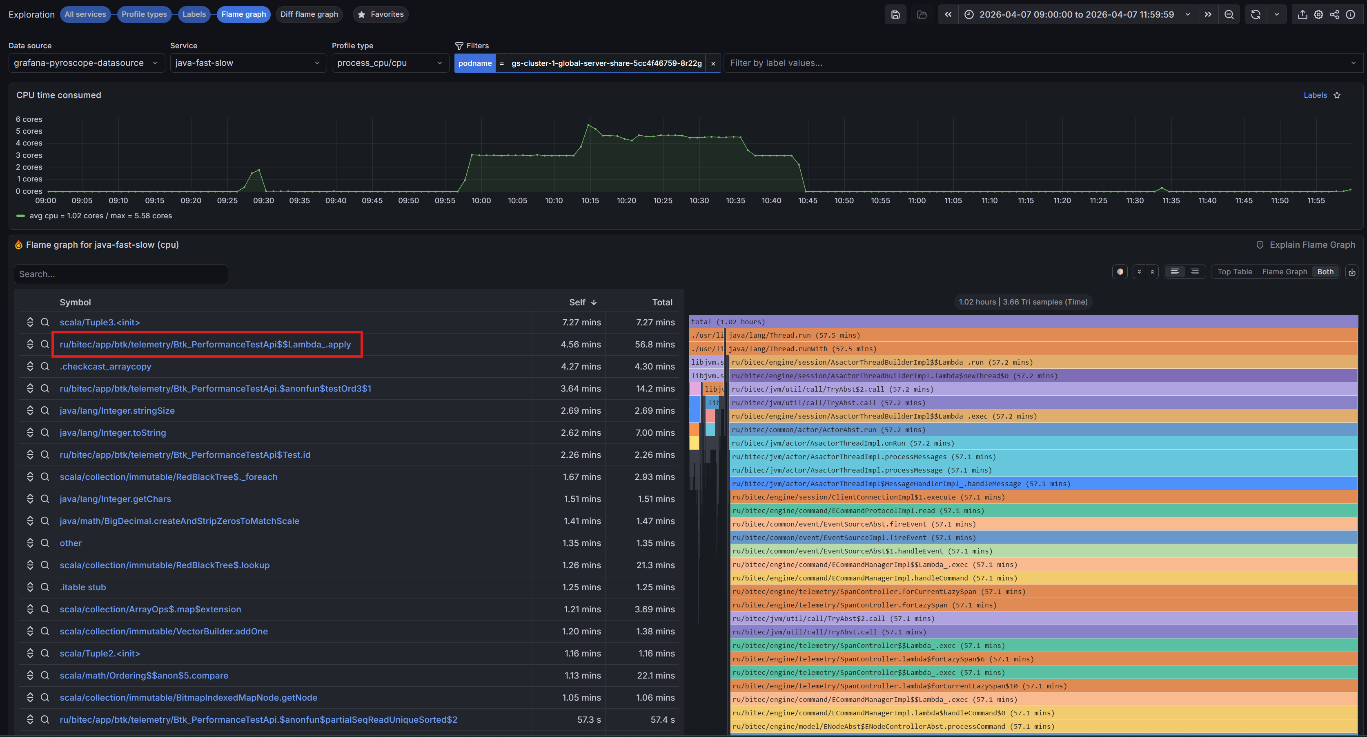
Рисунок 5. Выявление проблемного участка на Flame Graph
В рассматриваемом примере на Flame Graph определяется проблемный участок прикладного решения:
ru/bitec/app/btk/telemetry/Btk_PerformanceTestApi$$Lambda_.apply
Для получения дополнительной информации необходимо выбрать соответствующий участок Flame Graph и открыть раздел
Function Details, где отображаются детализированные сведения о выбранной функции.
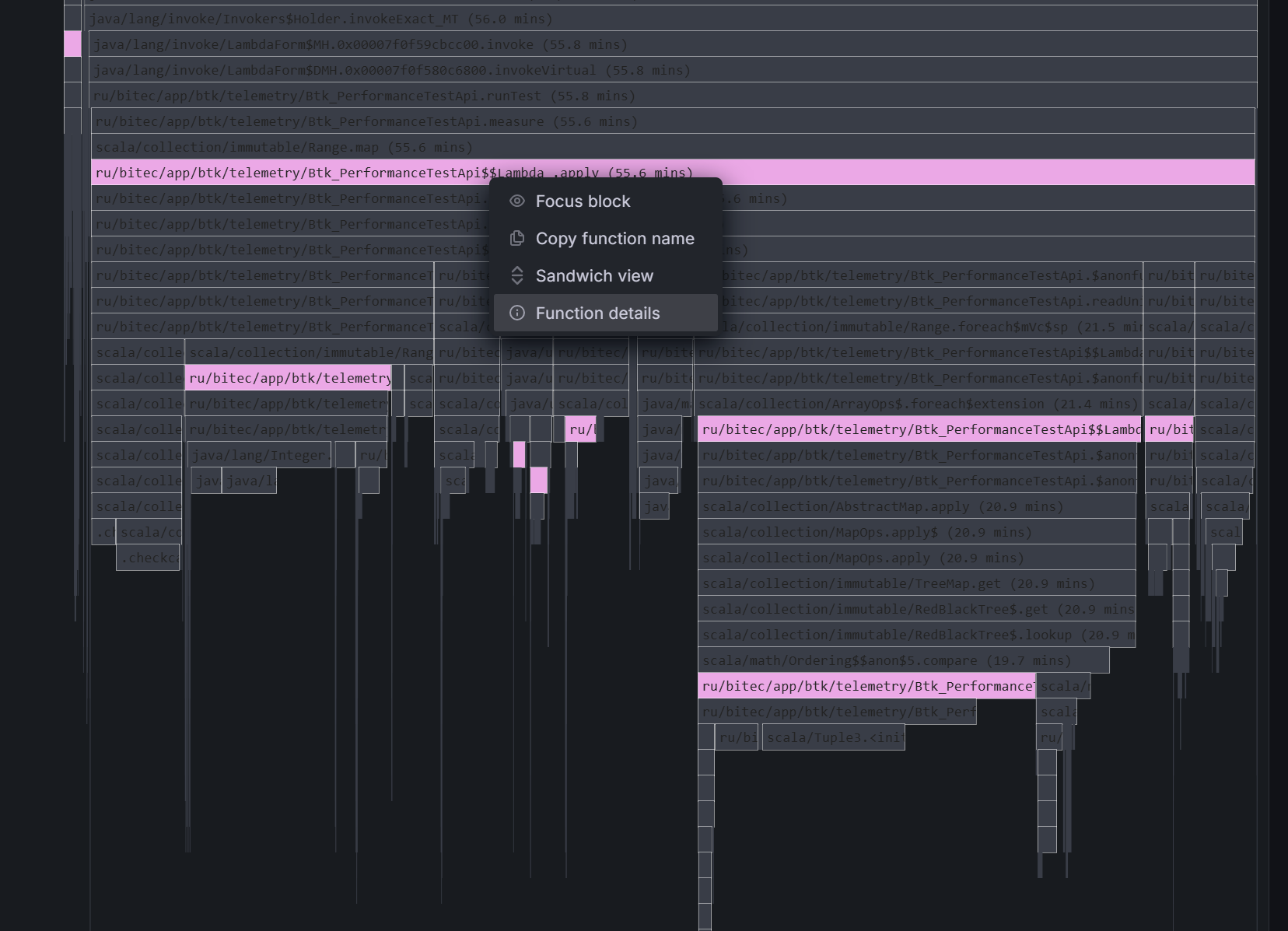
Рисунок 6. Просмотр сведений в разделе Function Details
Вывод по результатам анализа#
В рассматриваемом примере источник проблемы был установлен корректно: в целях тестирования с высокой частотой запускался
тест Btk_PerformanceTestApi, что привело к избыточной нагрузке на систему.
В эксплуатационных сценариях по итогам анализа необходимо:
зафиксировать временной диапазон возникновения проблемы;
сохранить скриншоты дашбордов и результатов профилирования;
указать проблемный
pod;указать выявленный участок кода;
передать собранные материалы разработчикам Global для дальнейшего анализа и устранения причины.
Состав информации для передачи разработчикам#
При эскалации инцидента рекомендуется передавать следующие данные:
Данные |
Описание |
|---|---|
Среда |
Наименование стенда, контура или эксплуатационной среды. |
|
Пространство имен, в котором наблюдается проблема. |
Период аномалии |
Дата и время начала/окончания повышенной нагрузки. |
Проблемный |
Полное имя |
Скриншоты мониторинга |
|
Тип профиля |
CPU или RAM, в зависимости от того, где проблема проявляется наиболее явно. |
Проблемная функция, класс или модуль |
Название участка, вызвавшего наибольшую нагрузку. |
Дополнительное описание |
Краткое описание наблюдаемого поведения и действий, предшествовавших росту нагрузки. |
Собранные материалы позволяют разработчикам быстрее воспроизвести проблему, определить причину повышенной нагрузки и подготовить исправление.